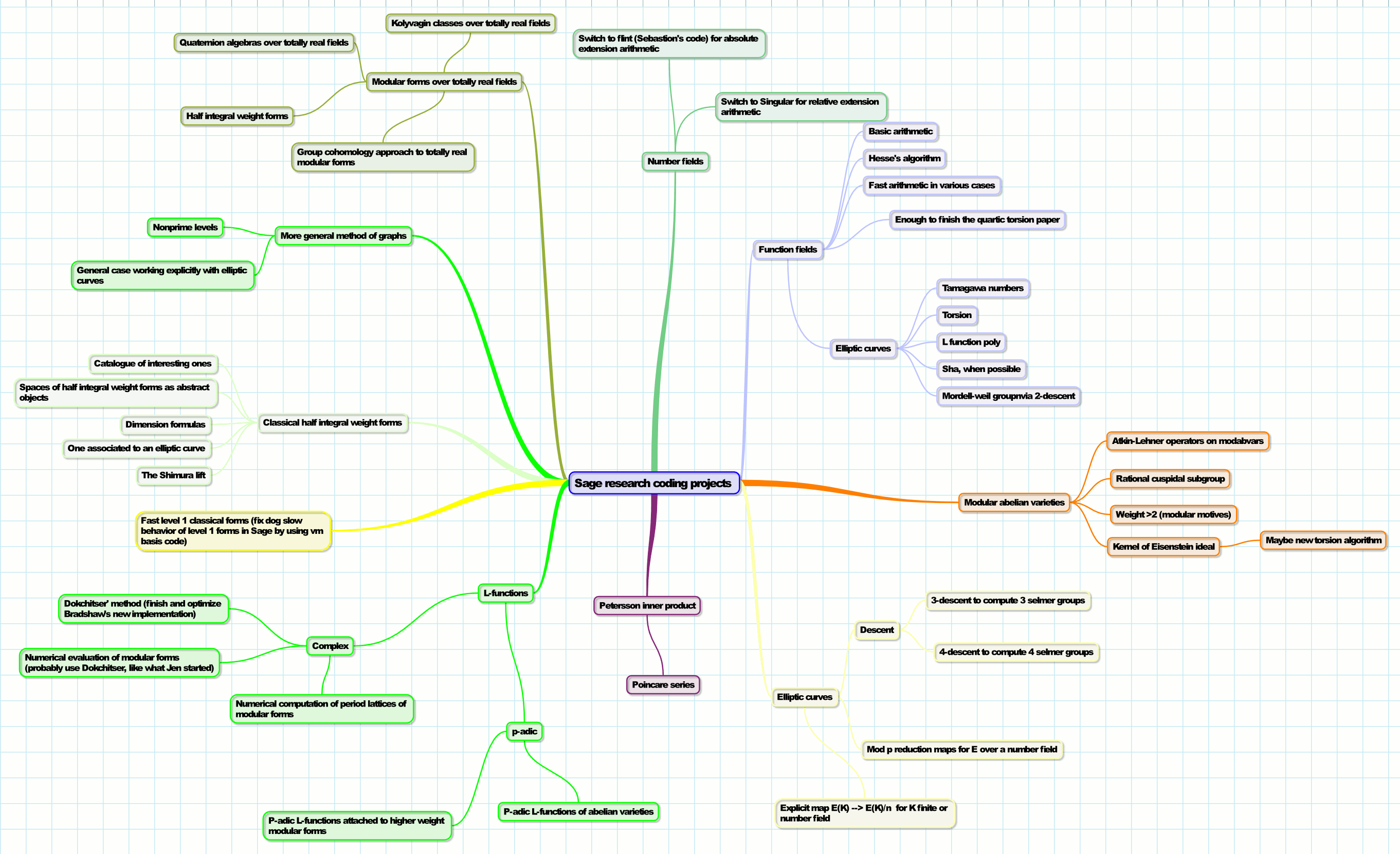
I made a diagram that illustrates most of the algorithms I wish Sage had to support my current mathematical research program. I am focusing most of my Sage development effort on ensuring that these get implemented as soon as possible. I will not depend on anybody else to help me with any of this, though if people would like to help in various ways that would be greatly appreciated. Over half of these are in the closed commercial Magma software already, which makes it much easier for me to implement them in Sage.
Research Versus the Goals of the Sage Project
A concern I have is that there might be disagreement in the Sage community about some of the design decisions that are necessary to support the implementation of my planned algorithms. For example, improving number field arithmetic to be dramatically faster requires making some sacrifices so that the implementation takes one week instead of two months (e.g., fundamentally depending on FLINT for basic arithmetic, which at least one Sage developer will be quite unhappy about). Even though I'm the leader of the Sage project, I won't just add code to Sage that a lot of people don't like. However, implementing everything planned here is a lot of work, and given the time and resources I have available, it will be impossible to fully document and test everything up to the standard necessary for inclusion in Sage. If this gets to be a nontrivial problem, I will maintain my own alternative ``fork'' of Sage, which I'll distribute separately. It will have `bleeding edge'' code that I'm developing, and I'll make full source releases available on a separate website, but I will not have to worry about constantly updating packages (like Maxima and Scipy) that are irrelevant to my research. The architecture of Sage makes creating such a fork easy, and of course I know how to manage this. In a few years, once I've built everything and complete the research I plan to do with it, I can spend the time merging back the good parts into mainline Sage. I know that several other Sage developers (e.g., Nick Alexander, David Roe, etc.) do something similar, since their personal research is so important to them, and getting code into Sage is overly difficult. It is very important that I acknowledge this tension, because currently the demands of "publishing" code in Sage -- and indeed of maintaining Sage as a general purpose system -- are so tough that they make genuine development of Sage as a research tool too difficult. Solution: create something that isn't Sage.
The Diagram
Here is the diagram. It is a tiny picture, but if you click on it you should get a bigger PDF that you can zoom into (if you are using Linux, download this PNG instead).
{kind=link}

I will spend the rest of this post discussing the first few algorithms at the top of the diagram, and my motivation for implementing them. Future posts will address the rest of the algorithms.

Number Fields
The top of the diagram lists number fields, and the two projects involve greatly speeding up basic arithmetic in Sage with elements of number fields. This is important to my research, since I intend to do explicit comptutations with elliptic curves and modular forms over number fields, including making large tables, hence fast arithmetic is important. Arithmetic in some cases in Sage is ridiculously slow, especially for relative fields. Fixing this involves switching from using NTL for all number field arithmetic to using FLINT (via Sebastian Pancratz's new rational polynomials) for absolue fields and Singular for relative extensions. I spent some time on this project and the results are at Trac 9541, but the code there should not be used as is. Instead, I'll finish this project by extracting out the best ideas from those patches, and adding more. The main idea for relative number fields is to create a C interface (written in Cython!) to Singular for computing with transcendence degree 1 function fields over the rational numbers. The other lesson I learned when working on Trac 9541 is that it is orders of magnitude easier to delete all code related to using NTL for number fields instead of trying to simultaneously support several different models for numbers fields.
Function Fields
Continuing clockwise, the next cluster of algorithms involves function fields of transcedence degree 1 over the prime subfield, i.e., function fields of algebraic curves. Function fields are important for my research because an application of explicit Riemann-Roch spaces and divisor reduction is a key step in completing a paper on torsion points on elliptic curves over quartic fields that I'm writing with Kamienny and Stoll. Function field arithmetic, rings, ideals, polynomial factorization, norm, traces, ``Poppov reduction'', etc., are the subject of Trac 9054, which should be relatively easy to finish. The next step is to implement Florian Hesse's algorithm for Riemann-Roch spaces, by following the description in Florian's papers and talks on the topic. Next, I'll have to implement divisor reduction and computation of maximal orders (normalization of curves). I suspect that Chris Hall will help. Parallel to this, it is also a good idea to use the same code as in the number field case to make basic arithmetic in certain function fields much faster than the generic code of Trac 9054.Elliptic Curves over Function Fields
I am also interested in code for computing with elliptic curves that are defined over function fields (usually over finite fields). This is related to work of Chris Hall, Sal Baig, and others at recent Sage
Days on function fields. This code will make it easier to computationally explore function field analogues of new ideas related to the Gross-Zagier formula and the BSD conjecture. The main goals are to implement algorithms for computing every quantity appearing in the Birch and Swinnerton-Dyer conjecture, including torsion, Tamagawa numbers, L-functions, Mordell-Weil groups (2-descent), and regulators. Also, I need to implement code for doing computations with Drinfeld modules, since Drinfled modules provide the analogue of modular curves and Heegner points in the function field setting.
13 comments:
Is my PDF viewer broken or is sage_coding_projects_20100824.pdf missing text?
I don't see any text either, with xpdf on arch linux.
Sorry - the fonts in the pdf evidently don't work on Linux. They do work on some other OS's. I'll try toupload a hires png when i get to a computer...
Here's a PNG for those who don't have the necessary fonts installed:
http://img442.imageshack.us/img442/3100/sagecodingprojects20100.png
Just curious, what program did you use to make that graph? I like the layout of it.
I used the iThoughtsHD "mindmap" program on my iPad. Making diagrams such as this is one of the strong points of the iPad hardware.
By the way, using iThoughtsHD you basically do the layout of the "graph" by hand (literally, by moving elements around on the screen with your finger). I wasn't able to find any good (Apple) desktop programs for doing the same thing as well...
Interesting beginning to the post. The same thing is true about some of my (much less complex!) research code - the effort in bringing it up to speed for a new module would be much larger than just using it and instead spending extra time on improving Sage proper.
I wonder if this might cause problems in the main Sage project, though - would Sage lose a lot of momentum if a lot of people did this? Or could there be something akin to 'experimental packages' that at least made sure that the 'friendly forks' were acknowledged as part of the Sage ecosystem?
Same problem here!
I'm working with spectral elements with numerical and symbolic tools, so I mostly need scipy, and the symbolic component of Sage.
But I think it is not a good Idea, that everyone just forks his own, version, because then everyone does something else and community breaks appart.
But the main issue here is, that Sage is very large, so one cannot just install something new, without risking to disable many features.
I personally think there are 2 possiblities to solve this:
1) make an easier package managing system. Perhaps even considering to make a very small debian/ubuntu distro, that only contains relevant packages for sage, and run it in a virtualbox or something like that.
2) Make it possible to individualize sage, i.e. I i don't need some of the components, I just can disable them during my work.
Let's say we need package X but we don't need Package Y and the functionalities it provides, it should be possible to deinstall Package Y, and deactivate the functionalities.
I don't know if these are the best solutions, but I'm quite sure, that it should be a discussion about the problem that Sage grows larger and larger, and that it's getting more and more hard to maintain.
Just my 2 cents.
A solution to solve your problem with the difference in effort needed to make software for your own research and to make it into a stable sage release might also be to mimic the aproach that debian takes in it's release cycles. They are always maintaining three different versions, stable, testing and unstable. The ``fork'' you suggest could play a similar role as unstable in the debian release cycle: http://www.debian.org/releases/.
An argument for this model is that it has proved to work for several years at another large scale open source project.
An advantage (and maybe disadvantage) of this model is that there will be more pressure/motivation to get the research code into stable at a certain moment then in the "fork" model.
Another possibility is to maintain a somewhat public patch queues like is done with http://combinat.sagemath.org/patches/ which has worked fairly well for developing unstable code while still making it available to others and making it easy to contribute patches back to main Sage.
For a good mind map program for OS X, I recommend MindNode. There's a free version which would probably be fine for mind maps like this. I'm using MindNode Pro and MindNode Touch for my work.
Post a Comment